
The first Spark/Hadoop ARM cluster runs atop Cubieboards
<This article is from Chanwit Kaewkasi ‘s blog,thanks to Chanwit’s nice work>
The Big Data Zone is presented by Splunk, the maker of data analysis solutions such as Hunk, an analytics tool for Hadoop, and the Splunk Web Framework.

An ARM chip is not for processing Big Data by design. However, it’s been gradually becoming powerful enough to do so. Many people have been trying to, at least, run Apache Hadoop on top of an ARM cluster. Cubieboard’s guys have posted in the last August that they were able to run Hadoop on an 8-node machine. Also, Jamie Whitehorn seems to be the first guy who successfully ran Hadoop on a Raspberry Pi cluster, in October 2013. Both show that an ARM cluster is OK to up and run Hadoop.
But is it feasible to seriously do Big Data on a low-cost ARM cluster? This question really bugs me.
We know that is doing operations on disk. With the slow I/O and networking of these ARM SoCs, Hadoop’s MapReduce will really not be able to process a real Big Data computation, which average 15GB per file.
Yes, the true nature of Big Data is not that big. And we often do batch processing over a list of files, each of them is not larger than that size. So if a cluster is capable of processing a file of size 15GB, it is good enough for Big Data.
To answer this question, we have prototyped an ARM-based cluster, designed to process Big Data. It’s a 22-node Cubieboard A10 with 100 Mbps Ethernet. Here’s what it looks like:

The cluster running Spark and Hadoop
As we learned that Hadoop’s Map Reduce is not a good choice to process on this kind of cluster, we decided to use only HDFS then looked for an alternative, and stumbled upon Apache Spark.
It’s kind a lucky for us that Spark is an in-memory framework which optionally spills intermediate results out to a disk when a computing node is running out-of-memory. So it’s running fine on our cluster. Although the cluster has total 20GB of RAM, there’s only 10GB available for data processing. If we try to allocate a larger amount of memory, some nodes will die during the computation.
So what is the result? Our cluster is good enough to crush a single, 34GB, Wikipedia article file from the year 2012. Its size is 2-times larger than the average Big Data file size, mentioned above. Also, it’s 3-times larger than the memory allocated to process data.
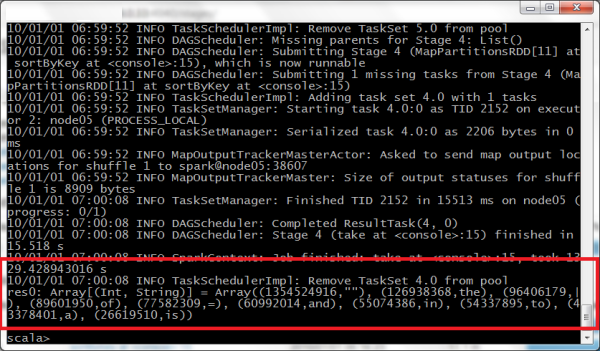
We simply ran a tweaked word count program in Spark’s shell and waited for 1 hour 50 mins and finally the cluster answered that the Wikipedia file contains 126,938,368 words of “the”. The cluster spent around 30.5 hours in total across all nodes.
The result printed out from Spark’s shell
(Just don’t mind the date. We didn’t set the cluster date/time properly.)
Design and Observation
We have 20 Spark worker nodes, and 2 of them also run Hadoop Data Nodes. This enables us to understand the data locality of our Spark/Hadoop cluster. We run the Hadoop’s Name Node and the Spark’s master node on the same machine. Another machine is the driver. The file is stored in 2 SSDs with SATA connected to Data Nodes. We set duplication to 2 as we have only 2 SSDs.
We have observed that the current bottleneck may be from 100 Mbps Ethernet, but we still have no chance to confirm this until we create a new cluster with 1Gbps Ethernet. We have 2 power supplies attached and the cluster seems to consume not much power. We’ll measure this in detail later. We are located in one of the warmest cities of Thailand, but we’ve found that the cluster is able to run fine here (with some additional fans). Our room temperature is air-conditioned to 25 degrees Celsius (or 77 degrees Fahrenheit). It’s great to have a cluster running without a costly data center, right?
Conclusions
An ARM system-on-chip board has demonstrated an enough power to form a cluster and process non-trivial size of data. The missing puzzle-piece we have found is to not rely only on Hadoop. We need to choose the right software package. Then with some engineering efforts, we can tune the software to fit the cluster. We have successfully used it to process a single large, 34 GB, file with acceptable time spent.
We are looking forwards to develop a new one, bigger by CPU cores but we’ll keep its size small. Yes, and we’re seriously thinking of putting the new one in the production.
Ah, I forgot to tell you the cluster’s name. It’s SUT Aiyara Cluster: Mk-I.
***********************below is the Chinese tanslation***************************
首款用Cubieboard搭建起的Spark/Hadoop ARM集群
在大数据时代,我们熟知的Splunk作为数据处理引擎,能有效提供大块数据分析及解决方案,是常用的开发分布式程序的分析工具,Splunk Web还能快速实现对搜索结果深入分析的功能。
ARM CPU设计之初,并没有瞄准大数据处理方向,但随着快速地架构优化和升级,目前看来已经非常接近或完全达到实现大数据处理的能力。在这个推进过程中,许多人一直试图在ARM集群之上运行 Apache Hadoop。Cubieboard的工作人员去年8月已经发帖表示他们能够在8节点设备上运行Hadoop。此外,Jamie Whitehorn 似乎是在Raspberry Pi上成功运行Hadoop的第一人,这在2013年10月已经成功实现。这都表明了ARM集群是可以运行Hadoop的。
但在低成本的ARM集群上处理大数据,这可行吗?这个问题确实困扰了我。
我们知道,Hadoop的 Map Reduce是在磁盘上运行的。通过ARM SoC进行网络数据传输,I/O速度还是有些慢,Hadoop的Map Reduce确实不能够进行平均大小为15GB的大文件计算。
是的,大数据实质上并没有那么大。我们经常对一系列的文件做批量处理,每个文件都没有那么大。因此,如果一个集群能够处理15GB大小的文件,那这对于处理大数据来说便足够了。
为了弄清这个问题,我们制作了一个基于ARM的集群,用于处理大数据。这是一个22节点的Cubieboard A10,连接100 Mbps以太网。以下就是其外观:
集群运行Spark和Hadoop
当我们了解到Hadoop的Map Reduce并不是处理这种集群的理想选择,我们决定只使用HDFS,然后找了一个替代方案,在这过程中偶然发现了Apache Spark,这个内存架构,能够根据实际情况将中间计算结果溢出到磁盘上,帮助解决计算节点内存不足的问题,从而实现集群的顺畅运行。虽然集群目前的运行情况还有待进一步优化,存在一些不足,例如:实际参与数据处理的内存不到50%;如果进行内存使用分配的提升,还会存在部分节点死机的现状,但这些都无法抹去集群所具备的真刀真枪运算优势,就拿“2012年至现在的大小为34GB(是一般大数据文件的2倍,内存处理资源占用量是一般情况下的3倍)的单个维基百科文档”来进行举例说明:集群在Apache Spark架构下,进行单个词“the”的搜索汇总,大约用了1小时50分钟就给出了该维基百科文件供包含:126,938,368单词“the”的结论。不用这个架构,同样的集群,花费的时间达到30.5小时。
从Spark shell打印出来的结果,(不要介意日期,我们没有正确设置集群的日期/时间。)
设计和观察
我们建起了20个Apache Spark工作节点,还建了2个Hadoop节点,用以充分对比Apache Spark 和 Hadoop 架构带来的不同的数据处理能力。我们在同一台设备上运行Hadoop的名称节点和Spark主节点,而另外一台设备安装驱动程序。文件存储在2个固态硬盘上,采用SATA连接到数据节点。我们设置为2个副本,因为我们只有2个固态硬盘。
我们观察到,目前的瓶颈可能在于100 Mbps以太网,但是我们仍然没有机会证实这一点,直到我们创建了一个1Gbps以太网的新集群。我们连接了2个电源,集群似乎没有消耗多少电量。我们将在后面详细测量这一点。我们的所在地是泰国最热的城市之一,但我们发现,集群能够在这里很好地运行(额外使用了一些风扇)。我们使用空调将房间温度保持在25摄氏度(或77华氏度)。不必使用昂贵的数据中心来运行一个集群挺不错,对不对?
结论
一个ARM系统芯片主板已经表现出了足够的能力来形成集群和处理较大的数据。我们找到难题破解答案就是不要只依赖于Hadoop。我们需要选择合适的软件包,通过一些技术工作来调整软件以适应集群。我们已经成功地利用该集群在可接受的时间内处理了一个34 GB的大型单个文件。
我们正期望通过CPU核心来开发一个全新的更大的产品,但我们会尽量使其小巧。是的,我们正在认真考虑新产品的生产。
对了,我忘了告诉你们这个集群的名称:SUT Aiyara Cluster: Mk-I。
Leave a Reply
You must be logged in to post a comment.